Entscheidungen, Entscheidungen, Entscheidungen… In der „guten alten Zeit“™ war die Welt einfacher – zumindest wenn es darum ging zu entscheiden, welche Datenbank man nimmt. Es ging im Prinzip nur um die Entscheidung, welchen Hersteller man bevorzugt (und ob man sich den Preis pro CPU leisten mag). Meist war es eine Datenbank, die SQL spricht und die Daten in Form von Tabellen ablegt. Das hat sich in den letzten zehn Jahren nachhaltig geändert.
Strukturiert oder nicht strukturiert?
Der auffälligste Unterschied zwischen relationalen Datenbanken wie DB2, Oracle DB, MySQL, MariaDB, MS SQL Server oder PostgreSQL (siehe https://en.wikipedia.org/wiki/Comparison_of_relational_database_management_systems) und NoSQL-Datenbanken wie Redis, MongoDB, CouchDB oder Cassandra (siehe https://en.wikipedia.org/wiki/NoSQL) ist, ob die Datenbank ein festes Schema für die Daten vorschreibt oder nicht. Um diesem wichtigen Unterschied Rechnung zu tragen spricht man daher bei letzteren auch häufig von Schema-losen Datenbanken.
Vorteil der Schema-behafteten Datenbanken ist, dass die strukturelle Integrität der einzelnen Datensätze von der Datenbank erzwungen werden kann. Alle der oben aufgeführten Datenbanken ermöglichen es über die Speicherung der Daten hinaus direkt im Server kleine Programme (stored procedures) laufen zu lassen. Wenn man ein bisschen masochistisch veranlagt ist – ich spreche da aus Erfahrung 😀 – kann ein großer Teil der Business Logik einer Anwendung so vollständig in der Datenbank implementiert werden.
Völlig anders sieht es bei Schema-losen Datenbanken aus. Hier weiß die Datenbank initial nichts über die Form der Datensätze. Statt dessen ist es Aufgabe des Programms, welches die Daten schreibt, dafür zu sorgen, dass alles seine Ordnung hat. So ist es viel einfacher, heterogene Datensätze oder solche mit vielen optionalen Werten zu verarbeiten. In MongoDB ist z.B. jeder Datensatz als Dokument zu verstehen, dessen Inhalt und Struktur grundsätzlich erstmal egal sind.
Das alles hat mit Graphen erstmal nichts zu tun…
Das Domänenmodell: Firmen und Personen
Um die Unterschiede zwischen den beiden Ansätzen deutlicher zu machen und endlich zum eigentlichen Thema dieses Artikels zu kommen schauen wir uns ein einfaches Modell an. Es gibt zwei Arten von Entitäten, nämlich Personen und Firmen. Eine Person hat einen Namen, eine Adresse und ein Geburtsdatum. Eine Firma hat auch einen Namen, eine Adresse und einen Geschäftsführer.
Meet the Maiers
Ich darf vorstellen: Die Maiers.
- „Peter Maier“,“Kleiner Weg 1, 12345 Dorf“, „01.01.1970“
- „Ulrike Maier“, „Kleiner Weg 1, 12345 Dorf“, „01.01.1970“
- „Rolph Maier“, „Villenallee 1, 12121 Am See“, „01.01.1970“
- „Peter Maier“, „Villenallee 2, 12121 Am See“, „24.12.1968“
Und es gibt zwei Firmen in der Region
- „Macher GmbH“, „Hauptstraße 1, 12346 Stadt, Gewerbegebiet I“, „Rolph Maier“
- „Handel OHG“, „Hauptstraße 2, 12346 Stadt, Gewerbegebiet I“, „Peter Maier“
Speichern, bitte!
Diese Daten lassen sich leicht in einer Datenbank ablegen. Dabei bekommt jedes Element noch einen weiteren Wert in Form einer eindeutigen ID. Egal welche Datenbank man nimmt, es gibt immer einen solchen Primärschlüssel anhand dessen alle Einträge eindeutig unterschieden werden können.
Einmal ohne Schema…
Auch in einer Dokumentendatenbank wie MongoDB wäre es sinnvoll, die beiden Arten von Dokumenten zu Gruppieren, z.B. in den Collections „persons“ und „companies“. Das eigentliche Programm ist dann wie oben geschrieben dafür verantwortlich, die Dokumente in der passenden Sammlung zu speichern.
In MongoDB sähe das etwa so aus:
{
_id: 123,
name: "Peter Maier",
address: "Kleiner Weg 1, 12345 Dorf",
date_of_birth: "1970-01-01"
}
oder
{
_id: 234,
name: "Macher GmbH",
address: "Hauptstraße 1, 12346 Stadt, Gewerbegebiet I",
ceo: "Rolph Maier"
}
… und einmal mit
In einer SQL-Datenbank wie MySQL sähe das Ganze dann ungefähr so aus:
persons
| id [PRIMARY KEY, BIGINT] | name [VARCHAR(256)] | address [VARCHAR(256)] | date_of_birth [DATE] |
| 123 | Peter Maier | Kleiner Weg 1, 12345 Dorf | 1970-01-01 |
companies
| id [PRIMARY KEY, BIGINT] | name [VARCHAR(256)] | address [VARCHAR(256)] | ceo [VARCHAR(256)] |
| 234 | Macher GmbH | Hauptstraße 1, 12346 Stadt, Gewerbegebiet I | Rolph Maier |
Und was hat das jetzt mit Graphen zu tun?
Immer noch nichts 🙂 Spannend wird die Sache, wenn wir uns über die Relationen zwischen den Entitäten Gedanken machen:
- Wer arbeitet wo?
- Sind Peter und Ulrike Maier vielleicht verheiratet?
- Und welcher Peter Maier ist eigentlich der CEO der Handel OHG?
Unser Domänenmodell sieht vielleicht gar nicht so aus
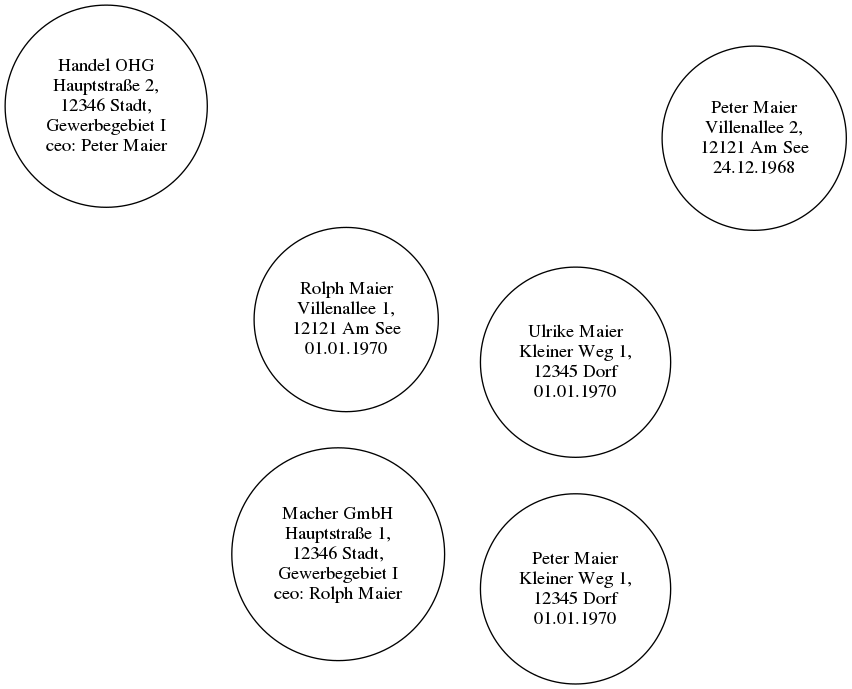
sondern so
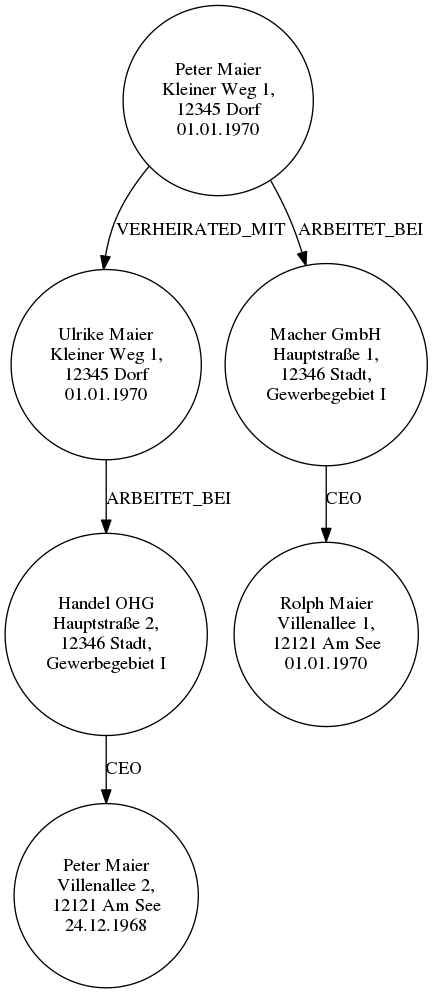
Das lässt einen durchaus an einen Graphen denken, oder?
Dinge in Beziehung setzen
An dieser Stelle wird die Sache bei den meisten Datenbanken komplizierter. Anders als der Name „Relationales Datenbank Management System“ erwarten lässt können RDBMS mit den Relationen zwischen einzelnen Einträgen (records) nicht direkt etwas anfangen. Abhilfe schaffen Fremdschlüssel-Beziehungen; also Tabellenspalten deren Inhalt die Schlüssel einer anderen Tabellen sind. Die Daten in der relationalen Datenbank sehen dann etwa so aus:
persons
| id [PRIMARY KEY, BIGINT] | name [VARCHAR(256)] | address [VARCHAR(256)] | date_of_birth [DATE] |
| 123 | Peter Maier | Kleiner Weg 1, 12345 Dorf | 1970-01-01 |
| 124 | Ulrike Maier | Kleiner Weg 1, 12345 Dorf | 1970-01-01 |
| 125 | Rolph Maier | Villenallee 1, 12121 Am See | 1970-01-01 |
| 126 | Peter Maier | Villenallee 2, 12121 Am See | 1968-12-24 |
companies
| id [PRIMARY KEY, BIGINT] | name [VARCHAR(256)] | address [VARCHAR(256)] | ceo [BIGINT, FK(persons.id)] |
| 234 | Macher GmbH | Hauptstraße 1, 12346 Stadt, Gewerbegebiet I | 125 |
| 235 | Handel OHG | Hauptstraße 2, 12346 Stadt, Gewerbegebiet I | 126 |
Um die weiteren Beziehungen abzubilden kann die Tabelle persons um weitere Fremdschlüssel-Spalten erweitert werden; z.B. married_to und works_at. Bei den unverheirateten Personen wäre married_to dann natürlich leer; bei Arbeitslosen works_at. Zudem muss der Status immer für beide Zeilen gepflegt werden weil verheiratet sein eine reflexive Relation ist. Noch komplizierter wird die Geschichte, wenn Peter der Arbeiter sich eine zweite Stelle sucht. Oder eine zweite Frau…
NoSQL Datenbanken machen das leider keinen Deut besser. Hier gibt es zwar noch die Alternative Relationen durch Unterdokumente abzubilden. Das ist allerdings nur sinnvoll, wenn die enthaltene Entität exklusiv der umfassenden zuzuordnen ist. Bei Kommentaren zu einem Blog-Artikel (hint, hint) wäre das also erstmal gut – so lange man nicht alle Kommentare eines Nutzers sucht. Dann wird es sehr schnell sehr langsam.
Such!
Langsam ist im Kontext einer Datenbank ein Wort, das reflexartig Schmerzen auslöst. Datenbanken sollen Daten ja nicht einfach nur speichern sondern vor allem gesuchte Daten schnell liefern. Das klappt immer ziemlich gut so lange die Datenbank Engine bei einer Anfragen auf Indizes zurückgreifen kann. Als Faustregel gilt, dass die Suche auf einem Index einen Aufwand von O(log(n)) hat. Greift kein Index, muss die Datenbank einen full table scan durchführen und der Aufwand steigt auf O(n). Das klingt erstmal nicht so schlimm, kann aber bei großen Datensätzen unangenehm lange dauern. Leider stehen schon bei einer so harmlosen Anfrage wie „Welche meiner Angestellten sind verheiratet?“ die Chancen ziemlich gut, dass kein Index greift.
Graph Databases to the Rescue!
Ist es also an der Zeit aufzugeben und lieber was mit Holz zu machen? Nein, natürlich nicht.
Zum einen ist die Sache nicht ganz so dramatisch wie ich (und einige Vertriebler) es gerade darstellen. Zum anderen zeigen Unternehmen wie Facebook, Google, Twitter und Co., dass sich auch sehr große Mengen eng verknüpfter Daten performant handhaben lassen.
In den letzten Jahren hat die Entwicklung von Graphendatenbanken rasant an Fahrt gewonnen. Während die eben genannten Unternehmen auf eigene Software setzen erfreut sich bei kleineren Firmen (ebay, Walmart etc.) Neo4j steigender Beliebtheit. Neo4j ist kurz gesagt eine NoSQL-Datenbank in der die Relationen zwischen den Dokumenten (bzw. Knoten) den gleichen Stellenwert wie die Dokumente selbst genießen. Das geht so weit, dass Relationen selbst Werte (Attribute) haben dürfen. In Neos Anfragesprache „Cypher“ sähen die Daten unseres Domänenmodells so aus:
CREATE
(pm1:Person {name:"Peter Maier", address:"Kleiner Weg 1, 12345 Dorf", date_of_birth:"1970-01-01"}),
(um:Person {name:"Ulrike Maier", address:"Kleiner Weg 1, 12345 Dorf", date_of_birth:"1970-01-01"}),
(rm:Person {name:"Rolph Maier", address:"Villenallee 1, 12121 Am See", date_of_birth:"1970-01-01"}),
(mg:Company {name:"Macher GmbH", address: "Hauptstraße 1, 12346 Stadt, Gewerbegebiet I"}),
(pm2:Person {name:"Peter Maier", address:"Villenallee 2, 12121 Am See", date_of_birth:"1968-12-24"}),
(ho:Company {name:"Handel OHG", address:"Hauptstraße 2, 12346 Stadt, Gewerbegebiet I"}),
(pm1)-[:MARRIED_TO]->(um),
(pm1)-[:WORKS_AT]->(mg),
(um)-[:WORKS_AT]->(ho),
(mg)-[:CEO]->(rm),
(ho)-[:CEO]->(pm2);
Im Vergleich dazu die graphviz-Datei, die ich zum Zeichnen des Bildes oben in dot füttere:
digraph G {
graph [overlap=false];
node [shape=circle]
pm1 [label="Peter Maier\nKleiner Weg 1,\n12345 Dorf\n01.01.1970"];
um [label="Ulrike Maier\nKleiner Weg 1,\n12345 Dorf\n01.01.1970"];
rm [label="Rolph Maier\nVillenallee 1,\n12121 Am See\n01.01.1970"];
pm2 [label="Peter Maier\nVillenallee 2,\n12121 Am See\n24.12.1968"];
mg [label="Macher GmbH\nHauptstraße 1,\n12346 Stadt,\nGewerbegebiet I"];
ho [label="Handel OHG\nHauptstraße 2,\n12346 Stadt,\nGewerbegebiet I"];
pm1 -> um [label="VERHEIRATED_MIT"];
pm1 -> mg [label="ARBEITET_BEI"];
um -> ho [label="ARBEITET_BEI"];
mg -> rm [label="CEO"];
ho -> pm2 [label="CEO"];
}
Such!
Auch das Suchen von Daten basierend auf der Beziehung zwischen Entitäten ist mit Cypher sehr einfach. Die Query MATCH (employee:Person)-[:WORKS_AT]->(:Company {name:“Macher GmbH“}), (employee)-[:MARRIED_TO]-(partner) RETURN employee, partner liefert paarweise alle verheirateten Mitarbeiter der Macher GmbH sowie deren Partner. Da die Richtung der [:MARRIED_TO] Relation nicht explizit angegeben wurde findet (MATCH’d) Neo Graphen, in der eine Relation in einer der beiden Richtungen definiert wurde.
Ist das denn schneller?
Die Suche nach der Macher GmbH dauert genauso lange wie bei jeder anderen Datenbank auch: O(log(n)) wenn ein Index auf der name-Property liegt und O(n), wenn nicht. Daran lässt sich nach aktuellem Stand der Technik nichts drehen. Der dramatische Unterschied liegt im Aufwand der Traversion von einem Knoten zum nächsten: O(1). Zudem ist es anders als bei einer Kreuztabelle gleichgültig, auf welcher Seite der Relation sich eine Entität befindet. Vom Ansatz many-to-many-Relationships in CouchDB über strukturierte IDs zu verwalten (siehe https://github.com/eHealthAfrica/couchdb-best-practices#n-to-n-relations) möchte ich besser gar nicht anfangen.
Das Arbeiten mit Relationen, gleichgültig ob 1-n oder m-n, ist sehr viel einfacher als in anderen Datenbanksystem. Um Ulrike Maier einen zweiten Job bei der Macher GmbH zu geben reicht
MATCH (u:Person {name:"Ulrike Maier"}), (c:Company{name:"Macher GmbH"})
MERGE (u)-[:WORKS_AT]->(c)
Sind Graphendatenbanken also die ultimative Lösung all unserer Probleme?
a
Tut mir Leid. Wenn es darum geht, sehr viele Daten statistisch zu verarbeiten um beispielsweise Mittelwerte etc. zu ermitteln sind Graphendatenbanken eher schlecht geeignet. Um die hohe Geschwindigkeit beim Lesen zu gewährleisten sind die Schreiboperationen zudem verglichen mit einigen anderen Systemen etwas langsamer.
Als grobes Daumenmaß kann man sagen
- Würde man das Problem im kleinen Maßstab mit einer Tabellenkalkulation lösen? Sieht das Domänenmodell wie eine Tabelle aus? Nimm eine SQL-Datenbank wie PostgreSQL!
- Werden viele Daten geschrieben, die eher wie Dokumente aussehen? Ist deren Struktur heterogen? Sind die Relationen zwischen den Entitäten gering oder liegt eine Baumartige Struktur vor? Dann nimm eine Schemalose Dokumentendatenbank wie MongoDB!
- Werden sehr viele, sehr einfache Daten geschrieben (z.B. Messpunkte, Zeitreihen)? Dann ist vielleicht Redis eine gute Wahl.
- Sind die Daten stark verknüpft? Sieht das Domänenmodell aus wie ein Graph mit vielen Pfeilen in alle möglichen Richtungen? Dann weißt du ja jetzt was zu tun ist 😉
Und wie weiter?
Auf https://neo4j.com/download/ gibt es die kostenlose Community Edition von Neo. Nach dem Entpacken in ein beliebiges Verzeichnis muss im Ordner bin nur der Befehl neo4j console ausgeführt werden. Nach wenigen Sekunden läuft die Datenbank und lauscht auf den Port 7474. Im Browser localhost:7474 öffnen, User und Passwort anlegen und schon kann man nach Herzenslust mit dem exzellenten Frontend von Neo rumspielen.
Mit MATCH (n) DETACH DELETE (n) lässt sich die Datenbank wieder leeren.
Und noch weiter…
- Ausführliches Tutorial mit Videos und Hands-on Aufgaben https://neo4j.com/graphacademy/online-course/
- Neo4j Knowledge Base https://neo4j.com/developer/kb/
- Spezifikation von Cypher https://neo4j.com/developer/cypher-query-language/
- Slack für Neo4j User https://neo4j-users.slack.com/
- Stackoverflow http://stackoverflow.com/questions/tagged/neo4j




















Schöner Beitrag Vielen Dank!
Ggf. die Graph-Diagramme etwas größer machen damit die Knotenbeschriftungen noch lesbar sind?
Und statt dot, wäre es doch sinnvoll die Visualisierung von Neo4j zu zeigen?
LOAD CSV wäre für Nutzer die von relationalen DB’s kommen sicher auch sehr interessant.
Viele Grüße Micha