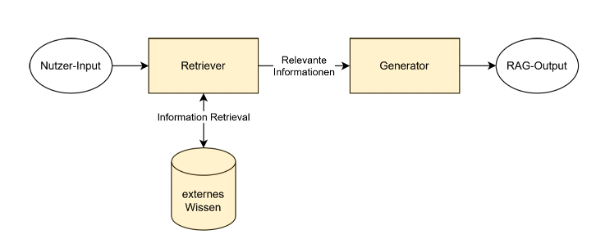
Retrieval Augmented Generation (RAG) ist ein hybrides KI-Framework, das generative Sprachmodelle (Large Language Models wie GPT, LLaMA oder Gemini) mit klassischen Information-Retrieval-Ansätzen kombiniert. Das Ziel dabei ist es, präzisere, kontextbezogene und faktengestützte Texte zu erzeugen. Dazu wird bei jeder Nutzeranfrage an ein KI-Modell eine oder mehrere externe Wissensquellen dynamisch hinzugezogen.
Statt sich allein auf das im Modell gespeicherte Wissen aus den Trainingsdaten des LLMs zu beziehen, greift RAG auf Vektordatenbanken zurück, um relevante Informationen abzurufen und in die Antwortgenerierung zu integrieren.
Warum ist RAG wichtig?
Große Sprachmodelle sind mächtig, aber nicht unfehlbar: Sie neigen zu Halluzinationen, enthalten nur statischen Trainingsstand und kennen kaum bis keine verlässlichen Quellen (schon gar nicht solche aus internem Unternehmenswissen).
RAG begegnet diesen Herausforderungen, indem es externe Wissensquellen in den Antwortprozess einbindet, ohne das KI-Modell neu und spezifisch auf eine Aufgabe trainieren zu müssen.
Aufbau eines RAG-Systems
Die typische RAG-Architektur besteht aus zwei Hauptkomponenten:
1. Retriever-Modul
- Wandelt Nutzereingaben per Encoder-LLM in semantische Vektoren (Embeddings) um.
- Führt eine semantische Ähnlichkeitssuche in einer Vektordatenbank (z. B. Pinecone, Weaviate, Elasticsearch) durch, in der beliebig viel relevantes Wissen gespeichert ist.
- Nutzt Techniken wie Approximate Nearest Neighbor Search (ANN) zur effizienten Auswahl relevanter Inhalte.
Was bedeutet semantische Suche?
Die semantische Suche ist das Herzstück des Retrieval-Schritts in RAG. Anders als bei traditioneller, schlüsselwortbasierter Suche, die lediglich exakte Wortübereinstimmungen prüft, zielt die semantische Suche darauf ab, den Sinn und Kontext einer Anfrage zu verstehen:
- Erstellung von Vektor-Embeddings: Sowohl Nutzeranfragen als auch internes Wissen, z.B. aus Dokumenten, werden in hochdimensionale Vektoren umgewandelt. Diese Embeddings repräsentieren die semantische Bedeutung eines Textes.
Beispiel: Die Fragen „Wie läuft der Release-Prozess bei uns ab?“ und „Welche Schritte sind nötig, um ein neues Feature in Produktion zu bringen?“ unterscheiden sich in der Wortwahl, zielen jedoch beide auf dieselbe Information, den unternehmensinternen Ablauf zur Softwarebereitstellung.
Eine semantische Suche erkennt diesen Zusammenhang und liefert beispielsweise das relevante Confluence-Dokument oder die interne DevOps-Richtlinie zum Release-Prozess, selbst wenn keines der Wörter exakt übereinstimmt. - Vergleich dieser Vektoren: Mit Distanzmetriken wie Kosinus-Ähnlichkeit wird berechnet, welche Inhalte am ähnlichsten zur Anfrage sind.
- Abruf relevanter Informationen: Auch wenn keine Schlüsselwörter übereinstimmen, erkennt das System inhaltlich passende Passagen und liefert sie an das LLM.
Vorteil für Unternehmen: RAG findet nicht nur „richtige Wörter“, sondern richtige Bedeutungen – selbst bei freier Formulierung oder Synonymen.
Vertrauen durch Nachvollziehbarkeit:
Ein zentraler Vorteil von RAG ist, dass die Quellen kontrollierbar und nachvollziehbar bleiben.
Unternehmen können genau bestimmen, welche Dokumente als Wissensbasis dienen und dem Nutzer auf Wunsch Zitate oder Verweise mitliefern.
2. Generator-Modul
- Ein Decoder-LLM (z. B. GPT-4, LLaMA 3) verarbeitet die gefundenen Informationen.
- Erstellt eine natürlichsprachliche, inhaltlich passende Antwort für den Nutzer, welche gestützt auf die vom Retriever gelieferten kontextuellen Daten generiert wird.
Diese Aufgabentrennung erlaubt es, stets mit aktuellen und sich verändernden Daten zu arbeiten. Auch dynamische Live-Quellen sind möglich:
RAG mit Echtzeitdaten
Neben Wikis, Datenbanken oder einzelnen Dokumenten können auch Live-Feeds wie Nachrichtenportale, interne Dashboards oder Social Media Streams angebunden werden.
So wird RAG zur Schnittstelle zwischen generativer KI und tagesaktueller Unternehmensrealität, was besonders wertvoll bei Marktbeobachtungen oder operativer Steuerung sein kann.
Vorteile und Nutzen von RAG
- Aktualität & Anpassungsfähigkeit: Inhalte lassen sich laufend aktualisieren, was ideal für dynamische Wissensbestände ist.
- Reduzierung von Halluzinationen: Durch den Rückgriff auf externe Wissensquellen sinkt die Gefahr faktischer Fehler.
- Kosteneffizienz: Kein teures Fine-Tuning notwendig und somit besonders attraktiv für KMU.
- Breite Datenkompatibilität: Unterstützt strukturierte (Datenbanken) und unstrukturierte Daten (PDFs, Wikis, Webseiten, Präsentationen u. v. m.).
- Transparenz & Kontrolle: Quellen lassen sich nachverfolgen, dokumentieren und auf Rechteeinschränkungen prüfen.
Einsatzszenarien
- Customer Support: Automatisierte, kontextreiche Antworten auf Kundenanfragen mit Zugriff auf interne FAQs, Dokumentationen oder Handbücher.
- Business Intelligence: Analyse komplexer Unternehmensdaten und Beantwortung analytischer Fragestellungen in natürlicher Sprache.
- Wissenschaft & Forschung: Unterstützung bei der Interaktion mit Forschungsdatenbanken, Erkennung von Mustern und Beschleunigung von Informationsabfragen.
Technologien und Tools für RAG
- LangChain – Orchestrierung von LLMs mit Retrieval-Modulen
- LlamaIndex (GPT Index) – Dokumentverarbeitung und -verlinkung
- Pinecone / Weaviate / FAISS / Milvus / Pgvector – Vektordatenbanken
- OpenAI API / Hugging Face Transformers – Zugang zu leistungsfähigen LLMs
- Live-Feeds, APIs, Dashboards – Anbindung von Echtzeitdatenquellen für aktuelle Inhalte
Fazit
Retrieval Augmented Generation ist mehr als nur ein technisches Konzept – es ist ein strategischer Baustein für moderne, vertrauenswürdige KI-Anwendungen.
RAG bietet:
- Zugriff auf internes Wissen, ohne Modelle neu trainieren zu müssen
- Faktenbasierte Antworten mit Quellen
- Skalierbare Kontrolle über Inhalt, Berechtigungen und Kontext
Gerade im Zusammenspiel mit semantischer Suche wird RAG zur entscheidenden Technologie für intelligente Informationssysteme. Es wird die Möglichkeit erschaffen, mit Daten jeglicher Art und Beschaffenheit zu interagieren und so die Vorteile generativer KI auf einfache Art und Weise ins Unternehmen zu holen.