In diesem Artikel wird das Tool Grunt vorgestellt. Grunt ist ein node.js Modul und erlaubt es, Routine-Aufgaben, die beim Bauen einer Webseite anfallen, zu automatisieren:
- Automatisches Kopieren der Projektdateien in passende Verzeichnisse
- Erkennen von Änderungen und Ausführung passender Schritte
- Automatisches Testen, sobald sich Tests oder Quellcode verändert
- …
Im Kern ist Grunt ein Task-Runner; ein Grunt-Task selbst wiederum ist eine Abfolge von Plugin-Aufrufen, die leicht an die eigenen Bedürfnisse anpassbar sind. Grunt kann auch durch eigene Tasks erweitert werden. Dazu ist nicht mehr erforderlich, als die Angabe des Tasknamens und der Reihenfolge der auszuführenden Plugins. Das Konfigurieren und Zusammenstellen der Plugins über Tasks ergibt somit ein sehr flexibles Buildsystem.
Zunächst wird das Grunt Command Line Interface benötigt. Es kann über den Node Package Manager npm installiert werden. Hierbei werden auch alle Abhängigkeiten aufgelöst.
npm install -g grunt-cli
Die Aufgabe dieses Tools ist es, die lokal installierte Grunt-Version unter Zuhilfenahme einer beiliegenden Konfigurationsdatei auszuführen. Nach dem Anlegen des Projektverzeichnisses werden folgende Schritte innerhalb des Verzeichnisses ausgeführt:
npm init
Hiermit wird eine package.json Datei erstellt, welche die Abhängigkeiten zu den eingesetzten node.js Modulen enthält. Werden im Laufe der Entwicklungsarbeiten weitere Module installiert, wird dies in package.json festgehalten. Außerdem beschreibt diese Datei unterschiedliche Eigenschaften des Projekts. Einige der möglichen Angaben werden bereits bei der Ausführung des Befehls abgefragt. Der Inhalt dieser Datei kann auch von Hand angepasst werden, allerdings ist hierbei das JSON-Format zu beachten.
Nun kann die aktuelle Grunt Version für das aktuelle Projekt installiert werden:
npm install grunt --save-dev
Damit wird Grunt im lokalen Verzeichnis node_modules installiert. Der Parameter –save-dev sorgt dafür, dass Grunt und eventuell notwendige weitere Module in package.json eingetragen werden.
Gruntfile.js
Diese Datei wird von Hand oder über den Templating Mechanismus angelegt. Für dieses Beispiel wird jedoch folgender Dateiinhalt vorausgesetzt, der in die Gruntfile.js kopiert werden kann:
module.exports = function(grunt) {
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
});
grunt.registerTask('default', []);
};
- Innheralb von grunt.initConfig() werden Grunt Plugins konfiguriert.
- grunt.registerTask(‚default‘,[]); erstellt einen neuen Task mit dem Namen ‚default‘. Der zweite Parameter ist ein Array, welches die auszuführenden Plugins enthält.
Die erste Aufgabe besteht nun darin, die erstellen HTML und Skriptdateien in ein Distributionsverzeichnis zu kopieren. Hierfür kommt das erste Grunt Plugin zum Einsatz.
grunt-contrib-copy
Das Plugin [grunt-contrib-]copy erweitert Grunt um die Fähigkeit Dateien und Ordner zu kopieren.
npm install grunt-contrib-copy --save-dev
Nach der Installation wird die Konfiguration für dieses Plugin in das Gruntfile.js eingetragen. Normalerweise erfolgt die Konfiguration, indem initConfig() um ein Objekt erweitert wird, das den Namen des Plugins trägt. Innerhalb dieses Objekts werden die Parameter für das Plugin angegeben. Einige Plugins erlauben es, sogenannte ‚targets‘ anzulegen. Ein ‚target‘ kann einen beliebigen Namen tragen (solange es gültiges JavaScript ist) und ermöglicht es, das gleiche Plugin für verschiedene Tasks mit einer anderen Konfiguration einzusetzen. Wird dem Plugin kein ‚target‘ übergeben, werden alle verfügbaren ‚targets‘ ausgeführt.
Gruntfile.js sollte nun so aussehen:
module.exports = function(grunt) {
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
copy: {
html: {
expand: true,
src: '**',
dest: 'dist/',
cwd: 'html/'
},
scripts: {
src: 'js/demoscript.js',
dest: 'dist/'
}
}
});
grunt.loadNpmTasks('grunt-contrib-copy');
grunt.registerTask('default', ['copy']);
};
Durch das ‚copy‘ Plugin existieren nun die Targets ‚html‘ und ’scripts‘. Diese Targets kopieren aus ihren jeweiligen Quellverzeichnissen alle Dateien in das Verzeichnis ‚dist‘, welches direkt unterhalb des Projektverzeichnisses liegt. ’src‘ gibt die Quelle, ‚dest‘ das Ziel des Kopiervorgangs an. Das Target ‚html‘ sieht etwas komplizierter aus. ‚cwd‘ (Change Working Directory) teilt dem Plugin mit, dass alle Pfadangaben für ’src‘ relativ zum Verzeichnis ‚html‘ erfolgen. Damit finden sich die Dateien nach dem Kopieren direkt im dist-Verzeichnis und nicht in dist/html/. Für diese Funktion muss ‚expand‘ zwingend auf true gesetzt werden.
Damit Grunt das Plugin benutzen kann, muss es zuvor mit grunt.loadNpmTasks(‚grunt-contrib-copy‘); geladen werden. Der Task ‚default‘ erhält zudem seinen ersten Eintrag. Wird der Task ‚default‘ ausgeführt, verrichtet das copy-Plugin seine Arbeit.
Tasks werden über den Aufruf grunt <taskname> gestartet. Im Falle von ‚default‘ ist die Angabe des Namens nicht notwendig. Wird Grunt nun mit dieser Konfiguration ausgeführt, legt es ein Verzeichnis ‚dist‘ an und kopiert die passenden Dateien aus src in das Verzeichnis.
(grunt-contrib-copy auf Github)
grunt-contrib-watch
Für die automatische Aktualisierung der Dateien im Buildverzeichnis wird grunt-contrib-watch eingesetzt.
- Zunächst die Installation: npm install grunt-contrib-watch –save-dev
- Grunt das Plugin bekannt machen: grunt.loadNpmTasks(‚grunt-contrib-watch‘);
Die Pluginkonfiguration für dieses Projekt sieht so aus:
//... für grunt.initConfig
watch: {
options: {
livereload: true
},
html: {
files: 'html/**',
tasks: ['copy:html']
},
scripts: {
files: 'js/**',
tasks: ['copy:scripts']
}
}
//...Task in grunt laden
grunt.loadNpmTasks('grunt-contrib-watch');
//...default Task aktualisieren
grunt.registerTask('default', ['copy', 'watch']);
Diese Konfiguration beschreibt, dass geänderte Script- und HTML-Dateien automatisch in das ‚dist‘ Verzeichnis kopieren sollen: Der Parameter ‚files‘ erhält ein Array mit Dateien, die auf Änderungen geprüft werden; wird eine Änderung festgestellt, werden die im ‚tasks‘ Parameter angegebenen Tasks ausgeführt.
Für das Zusammenspiel mit connect (s.u.) muss zusätzlich ‚livereload‘ auf true gesetzt werde.
Der watch-Task läuft dauerhaft weiter und blockiert nachfolgende Tasks. Er muss daher als letzter ausgeführt werden.
grunt-contrib-watch auf GitHub
grunt-contrib-connect
Grunt bietet mit grunt-contrib-connect auch die Möglichkeit, einen HTTP-Server zu starten.
//... Modul installieren
npm install grunt-contrib-connect --save-dev
//... Konfiguration
connect: {
localserv: {
options: {
port: 8080,
protocol: 'http',
base: 'dist',
livereload: 35729
}
}
}
//...Task in grunt laden
grunt.loadNpmTasks('grunt-contrib-connect');
//...default Task aktualisieren
grunt.registerTask('default', ['copy', 'connect:localserv', 'watch']);
connect unterstützt mehrere Serverkonfigurationen, die in den Optionen eines ‚targets‘ beschrieben werden. Hier wird eine Serverkonfiguration namens ‚localserv‘ erstellt. Der Server läuft auf Port 8080 und sein root-Verzeichnis ist ‚dist‘. In Kombination mit dem watch-Task kann automatisch der Browser aktualisiert werden, sobald Dateien geändert werden. In der Konfiguration oben wird connect mittels livereload gesagt, dass ein watch einen livereload-Server auf dem Port 35729 (kann bei Bedarf in der watch-Konfiguration angepasst werden) betreibt. ‚localserv‘ lauscht auf diesem Port und aktualisiert die Webseite bei Änderungen automatisch. Das automatisch ausgelieferte script livereload.js unterstützt alle modernen Browser.
grunt-contrib-connect auf GitHub
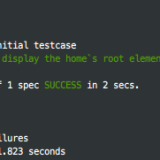
Testen mit Karma
Karma ist ein Test-Runner, der verschiedene Test-Frameworks ausführen kann. Das Tool startet einen Webserver, zu dem sich verschiedene Browser verbinden können. Karma führt für jeden Browser Tests durch.
Installation:
npm install karma --save-dev
npm install grunt-karma --save-devNach der Installation ist Karma unabhängig von Grunt ausführbar. Um es in den bestehenden Buildprozess einzubinden wird das Plugin grunt-karma benötigt. Die Konfiguration für Karma kann vollständig über Gruntfile.js erfolgen oder es kann auf eine Konfigurationsdatei verwiesen werden. Hier wird die zweite Variante vorgestellt:
Zunächst wird die Karma-Konfiguration mit karma init erstellt. Für dieses Beispiel sind folgende Optionen gewählt worden:
Which testing framework do you want to use ? Press tab to list possible options. Enter to move to the next question. > jasmine Do you want to use Require.js ? This will add Require.js plugin. Press tab to list possible options. Enter to move to the next question. > no Do you want to capture a browser automatically ? Press tab to list possible options. Enter empty string to move to the next question. > PhantomJS > What is the location of your source and test files ? You can use glob patterns, eg. "js/*.js" or "test/**/*Spec.js". Enter empty string to move to the next question. > js/demoscript.js > test/testscript.js Should any of the files included by the previous patterns be excluded ? You can use glob patterns, eg. "**/*.swp". Enter empty string to move to the next question. > Do you want Karma to watch all the files and run the tests on change ? Press tab to list possible options. > no
Die vorgenomme Konfiguration wird in der Datei karma.conf.js gespeichert. Karma ist ebenfalls in der Lage, auf Dateiänderungen zu achten und dann Tests erneut auszuführen. Da diese Aufgabe vom watch-Task erledigt wird, kann diese Option im letzten Schritt abgeschaltet werden. Bei den Dateiangaben ist ‚demoscript.js‘ das zu testende Skript und ‚testscript.js‘ das Testskript selbst, welches das Jasmin-Framework einsetzt.
Nun muss Karma in das Gruntfile eingebunden werden:
//... Konfiguration
karma: {
options: {
configFile: 'karma.conf.js',
reporters: ['progress'],
},
test: {
background: true
}
}
//... Watch Task erweitern
watch: {
options: // ...
html: // ...
scripts: // ...
karma: {
files: ['js/demoscript.js', 'test/testscript.js'],
tasks: ['karma:test:run']
}
}
//...Task in grunt laden
grunt.loadNpmTasks('grunt-karma');
//...default Task aktualisieren
grunt.registerTask('default', ['copy', 'connect:localserv', 'karma:test:start','watch']);
Die Konfiguration für Karma wird aus der entsprechenden Konfigurationsdatei geladen. Karma muss allerdings im Hintergrund gestartet werden, damit nachfolgende Tasks nicht blockiert werden. Dies wird mit dem Parameter ‚background‘ erreicht. Dem watch wird ein weiteres target hinzugefügt. Ändert sich an den Dateien etwas, führt Grunt den Karma-Task mit dem Target ‚dev‘ und somit alle Tests des Testskripts aus. Um das Starten des Karma-Servers nicht zu vergessen, wird registerTask um ‚karma:test:start‘ erweitert.
Nun kann mit dem Programmieren begonnen werden. Wer einmal erlebt hat, wie sich auf wie von Zauberhand mehrere Browser aktualisieren und sofort die letzte Änderung anzeigen, wird auf watch/connect nicht mehr verzichten wollen.